����
��������飺���գ��Ͽ���ѧ��ѧԺ���ڣ���ʿ����ʦ�����¹Ŵ�����ŵ����ס��Ŵ����ȷ���Ľ�ѧ���о���
�������ֻ����˳�����ǿ�ҵس���Ŵ�ͳͼ�����ҵ�ı��ݡ�Ӣ������ѧ�Ҳ��˹�����ϣ�Charles Handy���ڡ����������顷��The Elephant and the Flea: Looking Backwards to the Future��Hutchinson��Random House, London 2001��һ����ָ����������ȼ��ٶȵĸı佫�߸����ڵij����ҵģʽ��������Ϣ��ҵ�ġ�ȥ���ʻ�����dematerialization���͡�ȥ�н黯����disintermediation������ν��ȥ���ʻ������Dz���Ҫֽ�ţ�Ҳ�������ֻ�����ȥ�н黯����������ֱ�ӳ���ͼ�飬����Ҫ���������н顣����˾�Ĵ�ʼ�˱ȶ����Ǵģ�Bill Gates������Ԥ�Ե�2050�ֽ꣬��ͼ�齫�������������Ƕ�λ�Ļ�������Σ���������������������˵����һ���⡣
��������1������˹��ѧ�Ҹ����������������Grigori Perelman������Ӽ������루Poincare Conjecture��֤�������˵���ԵĹ��������2006��ȹ�����ѧ�����߽��ƶ��Ƚ���Fields����Ȼ����������Ļ����IJ�û�з�����������־�ϣ�����ֻ�ǽ������ָ�ճ����һ��ר�ſ�����ѧ���������ĵ���վ�ϣ����õ���֪ͨ�˼�λ��ѧ�ҡ���������Ļ���ζ�š����緢�����ѵõ�ѧ������Ͽɣ���Ԥʾ�ű�����������ʽ���������绯���ɡ�2008��10��28�գ���������Ӱ����ձ��������̿�ѧ���Ա�����Christian Science Monitor������ٷ���վ����������2009��4����ֹͣ����ֽ���ձ�����Ϊ�����ĵ����ձ����Ӷ���Ϊ����������������ֽ�ʰ��ձ���ȫ�����б�ֽ���������ͬʱ������������IT��־��PC Magazine��2008��11��19������������2009��2��ֹͣ����ӡˢ�棬����ȫ�����ֻ���ʽ���С�����Ϊ�������Ž���������������������Ž���Pulitzer Prize����Ҳ��2006���������������ݲμӸ��������ѡ����������ίԱ���Ѿ�����������ý�����ҪӰ�켰�Ϸ���λ��
��������2��ÿ��һ�ȵĵ¹������˸���չ��Frankfurt Book Fair���������Ϲ�ģ���Ĺ�����ͼ�鲩���ᣬ��������ͼ�鷢չ���Ƶķ���ꡣ2008��10��15����19�վ��еĵ�60�취���˸���չ�ϣ��ԡ����ֻ����桱Ϊ����IJ�չ�̶��361�ң���չ�IJ�Ʒ�����ֻ���Ʒ����30%����Ϊ�����רҵ��ʿ�ٰ��400�ೡ��У�50%���ϵĻ��ӭ��ͼ�����ֻ��йء�չ���ڼ䷢���ĵ��б�����ʾ����δ��60������ֻ�ͼ�齫��Ϊ����Ҫ�ij�����ʽ���ݱ��ع��ƣ���2018�꣬ȫ�����ͼ����г��ݶ������ͳͼ�顣
��������3���й������ѧ�о����ܹ������ų��������ί�У���1999����ÿ�����һ��ȫ���ԵĹ����Ķ������������Ѿ�������Σ���������ε����õ����ݣ�

�����ݹ�����ε���Ľ������������ؿ����ҹ�����ֽ��ͼ���Ķ��ʣ�ָÿ�����ٶ�һ����Ķ�����ʶ�����еı������ʳ����ߵ�̬�ƣ�2007���2005���½���14���ٷֵ㣬�½������Ǻܴ�ġ���ֽ��ͼ���Ķ����½��γ������Աȵ��ǣ��������Ķ��ʳ���Ѹ��������2007��������Ķ����Ѿ�������ֽ��ͼ���Ķ��ʡ����й�����������Ϣ���ģ�CNNIC��2009��1��13�շ����ġ���23���й��������緢չ״��ͳ�Ʊ��桷������2008��ף��ҹ����������ﵽ��2.98�ڣ���2007��������41.9%���������һλ���������ռ���Ϊ22.6%���״γ���21.9%��ȫ��ƽ��ˮƽ��������ˣ������й����˿ڻ����������ռ�����ȫ��������Һ͵�����ֻ���ڵ�87λ����������ҵ�ƽ���ռ��ʸ��Ǹߴ�51% ���������кܴ�IJ�ࡣ����Ԥ������δ������������ҹ����������û���������������������Ż������IJ����ռ��������Ķ��ʱؽ�������ߣ���ֽ���鿯���Ķ��ʱؽ������»�����ʹֽ��ͼ�����ٵ�����Σ��Խ��Խ���ء�
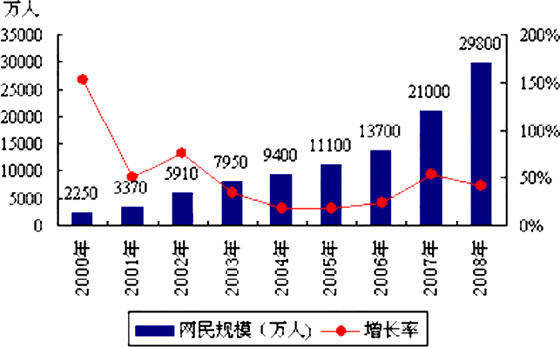
2000-2008���й������ģ��������ͳ��ͼ����CNNIC���棩
������Щ��ʵ�����ر����������ѽ�����һ�����ֻ��Ķ�����ʱ����
������ô��ֽ��ͼ����Ķ���ΪʲôԽ��Խ���أ�������Ϊ�����ͼ����ȣ�ֽ��ͼ��ȱ��ܶ࣬������ʱ�䳤�������ɱ��ߣ��۸�Я�������㣬�������ռ�ÿռ���ܼ������ƣ��ȵȡ�����ͼ������ֻ������Dz����赲�ķ�չ���ơ����ּ���������ʹ���ǵ�ͼ��������ʽ���Ķ�ϰ�����ڷ�������ʷ�Եı��뵱����ֽ��ij��ְѱ��صļ���������ʷ��̨�����죬����ͼ�����������ζ��ֽ��ͼ��ľ�Ĺ���Ѿ�����������ʹֽ��ͼ������ή�������ڲ�Զ�Ľ���ȡ��ֽ��ͼ���������λ���Դ˷�չ���ƣ�ͼ����������ͼ���������������ͼ���Ӧ�������ѵ���ʶ��
����ĵ��ӹż�Ӧ���������
����Ŀǰ������ͼ�黹û��ͳһ�������������������������ǡ�����ͼ�����������Ȼ���ܸ�һ���У�Ҳ��������һ�ɲ���ġ���ͬ��ͼ�����ͣ���ͬ�Ķ��߶���Ӧ���в�ͬ�������������������ѧ����Ҫ�ĽǶ���̸һ������ĵ��ӹż�Ӧ������Щ����
����������Ϊѧ����Ҫ��������ӹż�Ӧ�����������
������һ���ı�Ҫ�ɿ�
�������ǶԵ��ӹż��������Ҫ���ж��ı��ɿ��ı���������
����һ�����ָ�ֽ�ʹż�һ����û�в������û�����֡����֡����֡����ֵ�����Ҫ����������һ��ܲ����ף�Ŀǰ���»�û���ĸ����ӹż����ݿ��˵û�в����������ʹ����ʱ�з��֡��硰�й������ż��⡱�������������־�������ʮ�ġ����������������ϴ������ƪ���������������Բ�������������������Ϊ����ʿ��֮������F������ƽɽ�û������������С���������L��һ���h�������yꖿh���x�L����ʮ���Y�������y�����Y��������������������ת��Ϊ����ʱ��ɵĴ����δ���������ʡ���ǰ���С�����ͨ�͡�һ�������й������ż��⡱������©���Ͽ���ѧ�����ѧ�о����ġ��������������������˾���й�����ѧԺ��������������������Ƶġ���ʮ��ʷȫ���Ķ�����ϵͳ���������顤�������ġ���Тǫ������ǫ��Ϊ������֮��ʷ�ǡ�½���д����ġ��Ժ��ﮇ���ơ������ﮇ��Ϊ�������������������õ伮���ݿ��е�һҳ��

��������ġ�![]() ���Ǹ����֣��������ּ���ԭ������
���Ǹ����֣��������ּ���ԭ������![]() ���������������Ԫ���ҡ��Ž��ϻ��Ҫ������ʮ�ˡ�ȥ�����b�����ˡ����£����ˣ�����Ҳ��֮ҹ�У��ִ�Ϧ�����㡣�ˣ�֮���У�����Ҳ���ִ�Ϧ��һ�㡣�����ִ�Ϧ�����㡱֮��Ϧ������
���������������Ԫ���ҡ��Ž��ϻ��Ҫ������ʮ�ˡ�ȥ�����b�����ˡ����£����ˣ�����Ҳ��֮ҹ�У��ִ�Ϧ�����㡣�ˣ�֮���У�����Ҳ���ִ�Ϧ��һ�㡣�����ִ�Ϧ�����㡱֮��Ϧ������![]() �����ˣ�֮���С�֮���ˡ�����
�����ˣ�֮���С�֮���ˡ�����![]() ���ɼ����ӹż��IJ�����DZȽϸߵġ�
���ɼ����ӹż��IJ�����DZȽϸߵġ�
�����������״������Ҫԭ�����ڣ�һ���棬�ż�����������Ƚϸ��ӣ�������ʶ�������ܲ����죬��������ʶ�������һ���棬������˾��ȱ����Ϥ�Ŵ������У����Ա������ͨУ����Ա����ʤ�ιż�У�Թ������������˽ϸߵIJ���ʡ�
�������Ǿ����ܵر���ױ����ֵ�ԭ���������˵���ױ�дʲô�����֣����ӹż�Ӧ��ʾʲô�����֡�������һ��������ױ��ķ�����ϵͳ��������Ҫ������ױ��С��ڡ���춡����ֲ��ã�������ϵͳ���п���ͳһ�á�춡����ױ��м��С������֣����С��K���֣�������ϵͳ���п���ͳһ�á��K����Ŀǰ���ٷ����ֵ��ӹż��������������ġ���������ʹ�ż�����������ʧ��һЩ�м�ֵ�Ĺż��ı���Ϣ��������ѧ���о�����Щ�������������������ϵĻ��ҡ����硶��ǡ���������z����֮�©{���ң���ǽԫ�����ǹ���������ġ�������p��i���ǡ�������������϶������˼�����ת��Ϊ���ġ�������ʹ��ྶͥ�ˡ���¿�������DZ���ų��ʡ������أ����������Ա弱�������ճ������Ҷ�������֮�ã�Ի����һŭ�֡��������������н����������Ա�ŭΪ�䣬����֮���ɣ���˼���������ʵ�ѡ�����˼��˵������Ϊ�˿��Ƽ�����ŭ��ë�����ڹ��ô����������ϡ���һŭ�֡����Ҷ��������Լ������ת���ɡ��uһŭ�֡�����˼�ͳ������ŭ�ˡ�һ��������ʷ�α��е������컭���о�������д�ġ���������ױ��ķ�����ϵͳ��������ĵ��ӹż������ڰѹż�ת��Ϊ������ϵͳ�ģ��Ǿ;�����Ĺż���Զ�ˡ�
������ô����Ϊʲô˵�������ܵر��桱�ױ����ֵ�ԭ������Ҫ��ȫ�������أ�������Ϊ�ż����д�������д������壬��д�������仯��ˣ�һ�����п�����ʮ����д�������ȫ��ԭ�ⲻ���������ڵ��ӹż�����Ŀǰ�ļ��������´��ںܶ����ѡ���ʹ�ܹ�������Ҳ��������ӵ��ӹż��������ɱ����Ӷ���Լ���ӹż������������ۡ����������ڱ����ᡰ�����ܵر��桱������֮��������ԭ�������Խ��Խ�ã��ؼ������������ܹ�������Ч����������ƽ��㡣
���������Ƨ����������ʾ
�������ֵ�������Լ��ʮ�������ң����г����ֲ�������ǧ�֣��������������Ƨ�֡�Ŀǰ�������еĵ��ӹż���δ�ܽ��Ƨ�ֵ�¼����ʾ���⡣������¼����ʾ��Ƨ�֣������÷��ڿ�ȷ��ű�ʾ��ȱ�����������ִ��棬���ӵ�����ͼƬ������˵��ƫ�Ե�������������ȣ����Ķ���������ϰ�����ͼ�ǹ�ѧ������ѧ���䡱�����š����㡷�е�һ����

����Ƨ���ñ�Ŵ��棬��ͷ���ֻ������롣���µ�ȫ����Ҳ����ˡ�
������ͼ����ͬ�������ĵ��Ӱ桶�Ŀ�ȫ�顷�С������ּ�����һ��һҳ������ʾ����¼����ʾ���֣�һҳ�Ͼ���35��������ʾ��
�����ⷽ��������õ���������õ伮���ݿ⣬��Ƨ�ֶ���������ʾ�������桶���š����㡷����һ����������õ伮���ݿ�����ʾΪ��

����������ˣ�������ʾ����Ҳ��Ȼ���١�����ͼ�еĺڿ��������ʾ���֣�

�����������Ƨ�ֵ�¼����ʾ������Ȼ�����뼼�����蹥�˵����⡣
����������ÿһ���鶼�а汾��Ϣ
����ͬһ�ż����ж��ֲ�ͬ�İ汾����ͬ�汾�־���ʱ�в��죬���û�а汾��Ϣ���ı��Ŀɿ����Ӻ�ʵ����ͽ����˵����ı���ʹ�ü�ֵ������ѧ���䡱û�а汾��Ϣ��ѧ���о���ֻ����Ϊ�����������������û����ҿɿ��İ汾ȥ��ʵ�����й������ż��⡱����ע���˰汾�������Ź���������⡣������Ԫ�E��տԨ�����ע�������ݡ�֪����ի���顷������ʵ��Ȼ������������ۿ������ղ��������м�Ҳ����������������硣ǰ���ƴ��߶ࡣ���졶֪����ի���顷���������ղ�����������ϯ����������ǰ�ޡ�����ǰÑ��������������ټ���Ԩ���Ŀ�ȫ�顷������ȫһ�£�˵�����ݵױ�Ϊ��Ԩ���Ŀ�ȫ�顷������֪���Ա���ˡ�֪����ի���顷����
������һ���棬�����ż�����Ӧ���úõİ汾��Ϊ�ױ�����������˲��õİ汾����ʹû�в����ָ��ֽ�ʹż�һ�£���Ҳ������������ĵ��ӹż����硰�й������ż��⡱��¼�ı�����ʷ��̫ƽ���ǡ����á��Ŀ�ȫ�顷����������õİ汾���ο̱������л����2000��Ӱӡ����ġ��α�̫ƽ���ǡ�����ϧ���й������ż��⡱û�в��ã�Ҳ��Ϊû�ж��հ汾��
�������ģ���������������
�������ӹż��������������ܹ����м�����������һ���������Ƶļ���������������ӹż�����Ҫ�ı�����ô���������㹦�������أ�
������1�������ٶ�Ҫ�졣һ��Ӧ�ڼ�����֮���г��ؼ�������ҳ���������Ŀ������һ��˳�����С�
������2���ܹ�������������ļ��������簴��������Ȼ����ȷ�������������������������������������ų�ʽ��������A+�����ַ�+B������������ȵȣ���Щ������ѧ���о��Ϸdz����ã���ϧĿǰ�ż������ļ��������ṩ�Ĺ��ܱȽ��٣�����������ȷ�������ṩ��ij�ֹ��ܵģ������ڲ������⡣������Ӱ桶�Ŀ�ȫ�顷�С��롱���������ǡ��������ѡ��������ѡ��롱���������ǡ��ij����������ڡ�һ�����ķ�Χ�������ǡ�һ��ҳ�桱�ķ�Χ����ʹ���롱���������ǡ��ļ���������û��ʲô�ô������й������ż��⡱�ṩ�����������Ĺ��ܣ���һ��ֻ��ѡһ������������ͬʱ��ѡ��ʹ�ò��ܷ��㡣���ھ������ij���������������ࡣ�������ţ�Ա�ġ��������Ź�Ҫ�������δ�����Լ�����ڴ������δ�½�衶���š�����������Ե�ʣ������������Ź�Ҫ���롶���š������������顣��������������ġ�������֤�����������ǫ�ġ�������֤�������ں�����������������ġ���ʫ��ע���������Ƶġ������ļ���ע�������ƴ������Dz����ʵġ�ע��һ��Ӧ����ע�ߵ�ʱ�������籱κ۪��Ԫ�ġ�ˮ��ע����Ȼ��ע�ͺ�����ˮ�����ģ������Dz��ܰ����������伮һ��������ǵ����༭���ı���Ӧ�����ı�������ʱ�����������ġ�ȫ��ʫ������ȫ���ġ����ı������ƴ��ģ���ȻӦ�����ƴ�������Ϊ���ij��������ؽ�Ҫ���Ŵ���ʱ�������ѧ���о���������Ӱ�졣
������3����������Ҫȷ�����ڹż��д������������⣬�Դ�½��˵�����ڷ��������⣬���Լ����ؼ���ʱһ��Ӧ����Ӧ�Ĺ������������ܰ������������һ�ζ�������������������統�����ԡ����L��Ϊ�ؼ���ʱ������ͬʱҲ�ܼ����������L������Ŀ����������統�����ԡ����ڡ�Ϊ�ؼ���ʱ��ͬʱ�ܼ�����P�ڡ��͡��P춡�����Ŀ��Ŀǰ�Ĺż��������߱�����������ܣ��д˹��ܵ�������dz����ܡ��硶�Ŀ�ȫ�顷���������������ܣ�������߰ѡ����塱�ķ�Χ�ŵúܿ��������������֡��͡�ͨ���֡����ڣ���������������һ�����Ч��Ϣ����������������ϰ������統��������С��M���ֵ�����ʱ���������С������͡�������Ҳһ���������������������ӡ�ʱ�������衱�������ڡ��������衱�������ڡ��������ӡ�����Ŀ�������У�����Щ�ص���Ŀ�����ų�����һ���棬һЩӦ��ͬʱ����������֣�����ȴ��Ϊ��ͬ���ֶ����ܼ��������©���������硰�ǰϡ�����Ҳд������![]() �������ԡ��ǰϡ�Ϊ������ʱ������
�������ԡ��ǰϡ�Ϊ������ʱ������![]() �������ϼ첻���������ֹ���������û�����ֹ��ܷ��㡣�������Ӧ�ϸ����ڡ��κ�����¶��ܻ������֡��ķ�Χ֮�ڣ�����ֻ�ή��ȷ�ʡ�һЩ������ϵͳ�Ĺż�����ֻ�����뷱��ؼ��ʣ������ü���ؼ��ʣ���Դ�½��ʹ��������鷳����Щ������Ȼ�з���������ܣ�������©���ٳ������ڡ��й������ż��⡱�������������ӿ��СƷ������ʮ���������С����١�һ�ʣ������롰���١�һ�ʽ��м���ʱ�����Ϊ�㣬���÷����ּ������ܼ����õ�����������������ҡ�ʱ�첻��д�������ӎr�������ϣ���֮��Ȼ����������ʱ�����롰���ϡ��������������롰��퍡����ܼ쵽����˵���ù�����û�й����ϡ�����һ�ָ��������ǣ������÷��廹�Ǽ��壬�������������硰�й������ż��⡱����������ҡ���ͬ�Σ����ݸ�־���������С�Ω�������ɣ�Ϊ���µ�һ���Ļ���������ʮ����������ԡ�Ϊ���µ�һ��Ϊ�ؼ��ʣ��������������������һ���ڿ������յIJ������ж��У���������伭������¼�����塢��лά�±ࡶ���౸Ҫ������ʮһ�ȣ����������ȴ��û�С��ԡ�������ʯ����Ϊ������ʱ��ֻ����������������ɽ���������е�1����ʵ���ϣ��������յġ����顷�������������־��������ǫ�����鲹ע���ж�����仰��ȴ�첻����������ѧ�߿��ż����ݿ�ļ������ж�ij��������ijһʱ����ij�����е����ޣ���������ӱ���Ŀǰ�Ĺż���������ȫ����ס��
�������ϼ첻���������ֹ���������û�����ֹ��ܷ��㡣�������Ӧ�ϸ����ڡ��κ�����¶��ܻ������֡��ķ�Χ֮�ڣ�����ֻ�ή��ȷ�ʡ�һЩ������ϵͳ�Ĺż�����ֻ�����뷱��ؼ��ʣ������ü���ؼ��ʣ���Դ�½��ʹ��������鷳����Щ������Ȼ�з���������ܣ�������©���ٳ������ڡ��й������ż��⡱�������������ӿ��СƷ������ʮ���������С����١�һ�ʣ������롰���١�һ�ʽ��м���ʱ�����Ϊ�㣬���÷����ּ������ܼ����õ�����������������ҡ�ʱ�첻��д�������ӎr�������ϣ���֮��Ȼ����������ʱ�����롰���ϡ��������������롰��퍡����ܼ쵽����˵���ù�����û�й����ϡ�����һ�ָ��������ǣ������÷��廹�Ǽ��壬�������������硰�й������ż��⡱����������ҡ���ͬ�Σ����ݸ�־���������С�Ω�������ɣ�Ϊ���µ�һ���Ļ���������ʮ����������ԡ�Ϊ���µ�һ��Ϊ�ؼ��ʣ��������������������һ���ڿ������յIJ������ж��У���������伭������¼�����塢��лά�±ࡶ���౸Ҫ������ʮһ�ȣ����������ȴ��û�С��ԡ�������ʯ����Ϊ������ʱ��ֻ����������������ɽ���������е�1����ʵ���ϣ��������յġ����顷�������������־��������ǫ�����鲹ע���ж�����仰��ȴ�첻����������ѧ�߿��ż����ݿ�ļ������ж�ij��������ijһʱ����ij�����е����ޣ���������ӱ���Ŀǰ�Ĺż���������ȫ����ס��
������4��������������Ӧ����ϸ�ij�����ʾ�����ܱ�ݵظ��ơ�һ�������ij���Ӧ�������ߡ����߳�����������������ƪ��������Ϣ�������ij����ŷ���ѧ����Ҫ��Ȼ��Ŀǰ��û�дﵽ��һ���ĵ������ס����Ŀ�ȫ�顷�г������ƵĹ��ܣ���ϧ����ֻ�������;��������ڼ�����������Ҫ�����й������ż��⡱5.0��ǰ�İ汾û�г������ƹ��ܣ����µ�6.0�����ڼ���������Ŀҳ������ʾ���������ڸ����ı�ʱ�ṩ�������ƣ���Ҳֻ�������;�����ʹ������ͨ�����첹�䳯�������ߡ�ƪ������Ϣ���ȽϷ��¡�
������5���������Ҫ��ͳ�����ݣ����ܿ�ݵش鿴���ơ�Ŀǰ��һЩ�����㿪ԭ�ĺ���ʾ���ǹؼ������ڵ���ƪ���µĿ�ͷ�������ǹؼ������ڵĶ��䣬�ؼ���Ҳ���ܸ�����ʾ��Ҫ�ҵ��ؼ������ڵĶ���ܷ��¡���Щ���ݿ�Ը���ԭ�ķ������ϣ��硰�й������ż��⡱����ֱ�Ӹ��ƣ�����������ر༭�����ڲ��ܸ��ƣ�����ÿ�����ֻ�ܸ���200�֣��ܲ����㡣���������߱���֪ʶ��Ȩ�������ǿ�������ģ���ֻ�ܸ���һС���ֵ�������������ʹ���ߵ�Ȩ�棬������Ϊ��ֱ�Ӹ���ȫ����ǰҳ��
�������壬�ܺܺõؼ��ݳ����ִ�������
������������ż����ݿ���Ҫ��װר�õ�������������ʹ������ɲ��㡣��ͬ�ĵ�ÿһ�����ݿ�������Ҫ��װ�����Ŀͻ��˳��ܲ������������״̬Ӧ�����ó������������IE���Ϳ��������ʵ��������õ伮���ݿ�Ҳ�Ѿ���������һ�㣬�����������ݿ�������߽��������õijɹ����顣��Ȼ����������Ƴ�һ�����кϹż������ͨ������Ҳδ�����ɣ���Ŀǰ����Ϊ�����������������Դ���˷ѣ����Ҹ�ʹ������ɺܶ��鷳��ʵ����ȡ��
����������������������һ����Ҫ���Ƶ�WORD���ִ���������ʹ�õģ�Ȼ����Щ���ݿ�����ϸ���ճ����ᷢ�����ҡ����粻�ٹż�����ע�ģ�ע��һ����������С�ֱ�ʾ������ѡ��Ŀ�ȫ�顷�и��ƵĴ�ע�ĵ�����ճ��WORD��ʱ�����е�ע��ȫ���ܵ����ĵ�ĩβ֮������ԭ��֮�£�ʹ��ֲ����������������ע�ġ�����֪����ע�ģ�Ҳ��������ľ����ĵ�ע�ġ������ѣ����ø����ݿ��е�ԭҳ����ϸ�˶ԡ���½��ʹ����һ��Ҫ�Ѹ��Ƶķ���������ת��Ϊ�����֣�������ת���ᷢ����������WORD�ķ���ת�����߰ѡ��Ŀ�ȫ�顷�и��Ƶġ��S���A٢��Ԫ��������תΪ����ʱ����Ԫ����ת�����ˡ�����������Ī�����������õ伮���ݿ��е���ЩƧ�ָ���ճ����WORD��������������������š��е�![]() �ָ��Ƶ�WORD�����������ⶼ�Ǽ����Դ������⡣
�ָ��Ƶ�WORD�����������ⶼ�Ǽ����Դ������⡣
�����ܶ���֮���ż������ֻ��DZ��洫����������ùŴ��伮�ĸ������ֶΣ�������Ҫ����ʵ��ֵ����Զ����ʷ���壬���йط���Ӧ��Я����������ʱ�������ͬӭ�����ֻ�ʱ������ս��
�������ڣ�2009-08-18